Python實現(xiàn)GPU加速的基本操作
GPU從計算邏輯來講,可以認(rèn)為是一個高并行度的計算陣列,我們可以想象成一個二維的像圍棋棋盤一樣的網(wǎng)格,每一個格子都可以執(zhí)行一個單獨的任務(wù),并且所有的格子可以同時執(zhí)行計算任務(wù),這就是GPU加速的來源。那么剛才所提到的棋盤,每一列都認(rèn)為是一個線程,并有自己的線程編號;每一行都是一個塊,有自己的塊編號。我們可以通過一些簡單的程序來理解這其中的邏輯:
用GPU打印線程編號# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): print (’threadIdx:’, cuda.threadIdx.x)if __name__ == ’__main__’: gpu[2,4]()
threadIdx: 0threadIdx: 1threadIdx: 2threadIdx: 3threadIdx: 0threadIdx: 1threadIdx: 2threadIdx: 3用GPU打印塊編號
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): print (’blockIdx:’, cuda.blockIdx.x)if __name__ == ’__main__’: gpu[2,4]()
blockIdx: 0blockIdx: 0blockIdx: 0blockIdx: 0blockIdx: 1blockIdx: 1blockIdx: 1blockIdx: 1用GPU打印塊的維度
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): print (’blockDim:’, cuda.blockDim.x)if __name__ == ’__main__’: gpu[2,4]()
blockDim: 4blockDim: 4blockDim: 4blockDim: 4blockDim: 4blockDim: 4blockDim: 4blockDim: 4用GPU打印線程的維度
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): print (’gridDim:’, cuda.gridDim.x)if __name__ == ’__main__’: gpu[2,4]()
gridDim: 2gridDim: 2gridDim: 2gridDim: 2gridDim: 2gridDim: 2gridDim: 2gridDim: 2總結(jié)
我們可以用如下的一張圖來總結(jié)剛才提到的GPU網(wǎng)格的概念,在上面的測試案例中,我們在GPU上劃分一塊2*4大小的陣列用于我們自己的計算,每一行都是一個塊,每一列都是一個線程,所有的網(wǎng)格是同時執(zhí)行計算的內(nèi)容的(如果沒有邏輯上的依賴的話)。
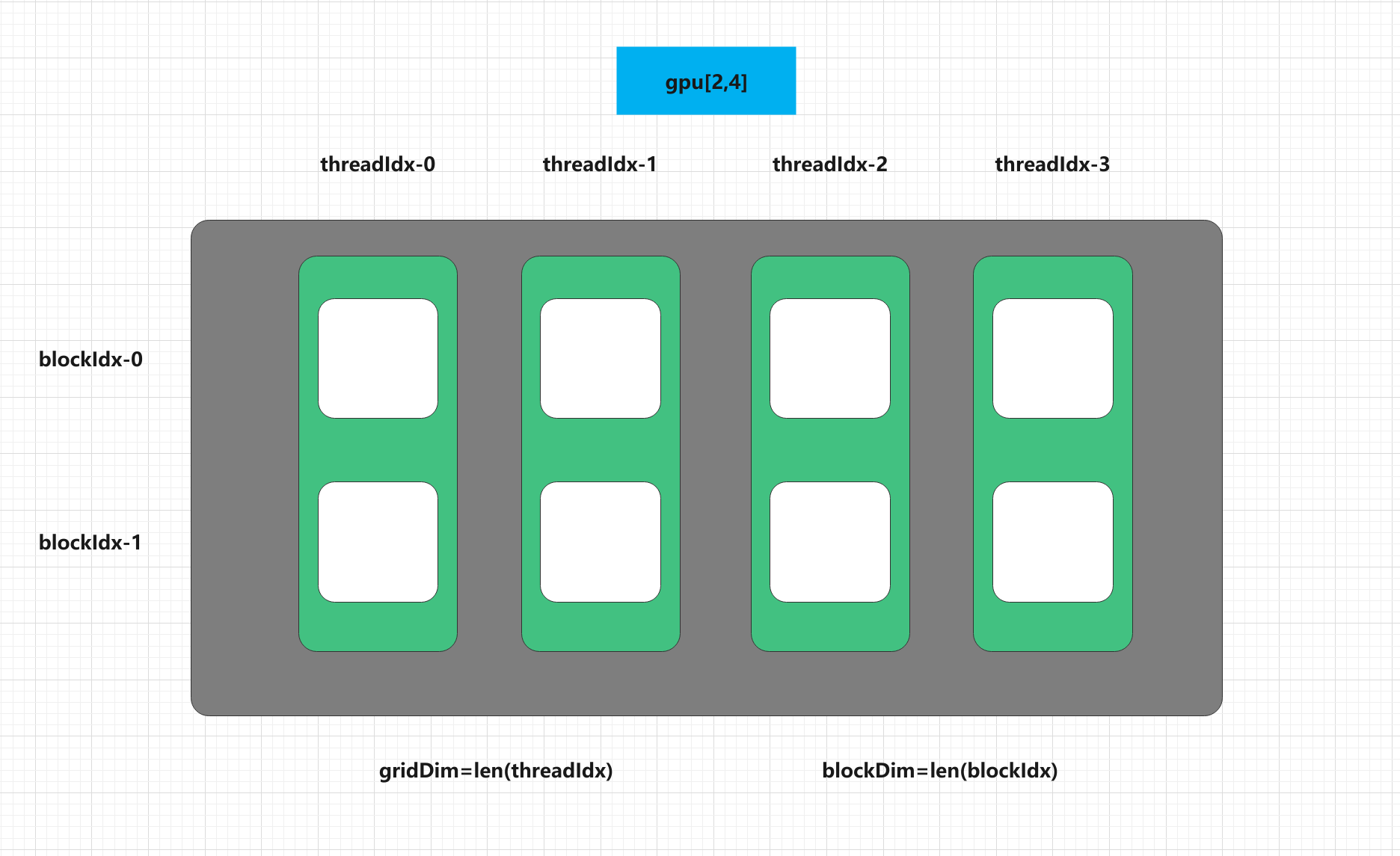
我們可以用幾個簡單的程序來測試一下GPU的并行度,因為每一個GPU上的網(wǎng)格都可以獨立的執(zhí)行一個任務(wù),因此我們認(rèn)為可以分配多少個網(wǎng)格,就有多大的并行度。本機的最大并行應(yīng)該是在(2^40),因此假設(shè)我們給GPU分配(2^50)大小的網(wǎng)格,程序就會報錯:
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): passif __name__ == ’__main__’: gpu[2**50,1]() print (’Running Success!’)
運行結(jié)果如下:
Traceback (most recent call last):File 'numba_cuda_test.py', line 10, in <module>gpu[2**50,1]()File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/compiler.py', line 822, in __call__self.stream, self.sharedmem)File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/compiler.py', line 966, in callkernel.launch(args, griddim, blockdim, stream, sharedmem)File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/compiler.py', line 699, in launchcooperative=self.cooperative)File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py', line 2100, in launch_kernelNone)File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py', line 300, in safe_cuda_api_callself._check_error(fname, retcode)File '/home/dechin/.local/lib/python3.7/site-packages/numba/cuda/cudadrv/driver.py', line 335, in _check_errorraise CudaAPIError(retcode, msg)numba.cuda.cudadrv.driver.CudaAPIError: [1] Call to cuLaunchKernel results in CUDA_ERROR_INVALID_VALUE
而如果我們分配一個額定大小之內(nèi)的網(wǎng)格,程序就可以正常的運行:
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): passif __name__ == ’__main__’: gpu[2**30,1]() print (’Running Success!’)
這里加了一個打印輸出:
Running Success!
需要注意的是,兩個維度上的可分配大小是不一致的,比如本機的上限是分配230*210大小的空間用于計算:
# numba_cuda_test.pyfrom numba import cuda@cuda.jitdef gpu(): passif __name__ == ’__main__’: gpu[2**30,2**10]() print (’Running Success!’)
同樣的,只要在允許的范圍內(nèi)都是可以執(zhí)行成功的:
Running Success!
如果在本機上有多塊GPU的話,還可以通過select_device的指令來選擇執(zhí)行指令的GPU編號:
# numba_cuda_test.pyfrom numba import cudacuda.select_device(1)import time@cuda.jitdef gpu(): passif __name__ == ’__main__’: gpu[2**30,2**10]() print (’Running Success!’)
如果兩塊GPU的可分配空間一致的話,就可以運行成功:
Running Success!
GPU的加速效果前面我們經(jīng)常提到一個詞叫GPU加速,GPU之所以能夠?qū)崿F(xiàn)加速的效果,正源自于GPU本身的高度并行性。這里我們直接用一個數(shù)組求和的案例來說明GPU的加速效果,這個案例需要得到的結(jié)果是(b_j=a_j+b_j),將求和后的值賦值在其中的一個輸入數(shù)組之上,以節(jié)省一些內(nèi)存空間。當(dāng)然,如果這個數(shù)組還有其他的用途的話,是不能這樣操作的。具體代碼如下:
# gpu_add.pyfrom numba import cudacuda.select_device(1)import numpy as npimport time@cuda.jitdef gpu(a,b,DATA_LENGHTH): idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x if idx < DATA_LENGHTH:b[idx] += a[idx]if __name__ == ’__main__’: np.random.seed(1) DATA_EXP_LENGTH = 20 DATA_DIMENSION = 2**DATA_EXP_LENGTH np_time = 0.0 nb_time = 0.0 for i in range(100):a = np.random.randn(DATA_DIMENSION).astype(np.float32)b = np.random.randn(DATA_DIMENSION).astype(np.float32)a_cuda = cuda.to_device(a)b_cuda = cuda.to_device(b)time0 = time.time()gpu[DATA_DIMENSION,4](a_cuda,b_cuda,DATA_DIMENSION)time1 = time.time()c = b_cuda.copy_to_host()time2 = time.time()d = np.add(a,b)time3 = time.time()if i == 0: print (’The error between numba and numpy is: ’, sum(c-d)) continuenp_time += time3 - time2nb_time += time1 - time0 print (’The time cost of numba is: {}s’.format(nb_time)) print (’The time cost of numpy is: {}s’.format(np_time))
需要注意的是,基于Numba實現(xiàn)的Python的GPU加速程序,采用的jit即時編譯的模式,也就是說,在運行調(diào)用到相關(guān)函數(shù)時,才會對其進(jìn)行編譯優(yōu)化。換句話說,第一次執(zhí)行這一條指令的時候,事實上達(dá)不到加速的效果,因為這個運行的時間包含了較長的一段編譯時間。但是從第二次運行調(diào)用開始,就不需要重新編譯,這時候GPU加速的效果就體現(xiàn)出來了,運行結(jié)果如下:
$ python3 gpu_add.py The error between numba and numpy is: 0.0The time cost of numba is: 0.018711328506469727sThe time cost of numpy is: 0.09502553939819336s
可以看到,即使是相比于Python中優(yōu)化程度十分強大的的Numpy實現(xiàn),我們自己寫的GPU加速的程序也能夠達(dá)到5倍的加速效果(在前面一篇博客中,針對于特殊計算場景,加速效果可達(dá)1000倍以上),而且可定制化程度非常之高。
總結(jié)概要本文針對于Python中使用Numba的GPU加速程序的一些基本概念和實現(xiàn)的方法,比如GPU中的線程和模塊的概念,以及給出了一個矢量加法的代碼案例,進(jìn)一步說明了GPU加速的效果。需要注意的是,由于Python中的Numba實現(xiàn)是一種即時編譯的技術(shù),因此第一次運算時的時間會明顯較長,所以我們一般說GPU加速是指從第二步開始的運行時間。對于一些工業(yè)和學(xué)界常見的場景,比如分子動力學(xué)模擬中的系統(tǒng)演化,或者是深度學(xué)習(xí)與量子計算中的參數(shù)優(yōu)化,都是相同維度參數(shù)多步運算的一個過程,非常適合使用即時編譯的技術(shù),配合以GPU高度并行化的加速效果,能夠在實際工業(yè)和學(xué)術(shù)界的各種場景下發(fā)揮巨大的作用。
到此這篇關(guān)于Python實現(xiàn)GPU加速的基本操作的文章就介紹到這了,更多相關(guān)Python GPU加速內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備