文章詳情頁
python - scrapy運行爬蟲一打開就關閉了沒有爬取到數據是什么原因
瀏覽:135日期:2022-08-05 15:09:38
問題描述
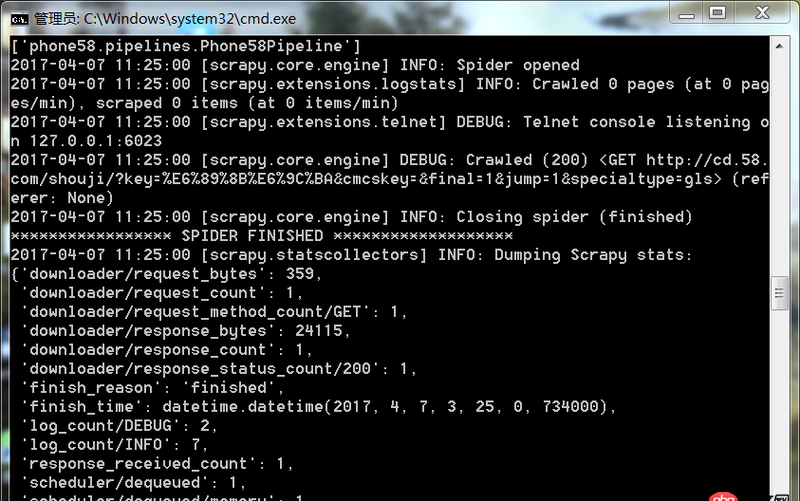
爬蟲運行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規則出錯,也就是說你的spider代碼里面的xpath(或者其他解析工具)的規則錯誤。導致沒爬取到。你可以把網址print出來,看看是不是[]
相關文章:
1. 我在centos容器里安裝docker,也就是在容器里安裝容器,報錯了?2. docker-compose中volumes的問題3. docker-machine添加一個已有的docker主機問題4. golang - 用IDE看docker源碼時的小問題5. docker不顯示端口映射呢?6. 在windows下安裝docker Toolbox 啟動Docker Quickstart Terminal 失敗!7. docker內創建jenkins訪問另一個容器下的服務器問題8. javascript - 最近用echarts做統計圖時遇到兩個問題!!9. docker容器呢SSH為什么連不通呢?10. mac里的docker如何命令行開啟呢?
排行榜

 網公網安備
網公網安備